SolarWinds „Hybrid Cloud Observability“ im Test – Überwachung hybrider Umgebungen
Die Installation von Hybrid Cloud Observability
Im Test spielten wir die Software auf einem Windows Server 2019 ein, der auf einer virtuellen Maschine unter VMware ESXi 7.0.3 lief. Diese Maschine verfügte über vier CPU-Kerne mit einer Taktfrequenz von 3,6 Ghz, 32 GByte RAM und 120 GByte Festplattenplatz. Als Datenbank verwendeten wir einen im Netz bereits vorhandenen Microsoft SQL-Server 2017. Laut SolarWinds lassen sich Testinstallationen der Software bereits auf Systemen einspielen, die über vier CPU-Kerne und acht GByte Arbeitsspeicher verfügen. Auf solchen Testsystemen ist es auch möglich, eine SQL-Server-Express-Datenbank zu verwenden, die auf der gleichen Maschine läuft. Die Installationsroutine bringt eine solche bereits mit.
Für den Test stellte uns SolarWinds eine Datei mit einem ISO-Image bereit, die die gesamte erforderliche Software enthielt. Nachdem wir dieses Image eingebunden hatten, startete gleich der Installationsassistent und empfing uns mit einem Willkommensbildschirm. Danach konnten wir uns entscheiden, ob wir eine Standardinstallation durchführen oder die Skalierbarkeits-Add-Ons einspielen wollten. Letztere stellen zusätzliche Dienste wie eine weitere Polling-Engine und einen weiteren Web-Server bereit und können in großen Umgebungen Verwendung finden. Wir entschieden uns an dieser Stelle für die Standardinstallation. Abgesehen davon will der Setup-Assistent noch wissen, ob er den erwähnten SQL Server Express installieren soll, oder ob eine bereits existierende Datenbank-Server-Installation zum Einsatz kommt. Zusätzlich fragt er auch noch die zu verwendende Sprache und den Installationspfad ab.

Nachdem alle Angaben gemacht wurden, testet der Assistent die Umgebung und führt die Installation durch. Bei uns stellte er in diesem Zusammenhang fest, dass auf unserem Server kein IIS vorhanden war und spielte diesen direkt mit ein. Der ganze Installationsvorgang gestaltet sich demzufolge recht unkompliziert. In unserer Umgebung dauerte das gesamte Setup etwa eine Stunde und es waren dabei keine Interaktionen von Mitarbeiterseite aus erforderlich. Uns fiel nur negativ auf, dass der Installationsassistent nach etwa zehn Minuten bereits sagte, das Setup sei zu 90 Prozent abgeschlossen. Für die restlichen zehn Prozent brauchte er dann nochmal fast 50 Minuten.
Die Erstkonfiguration und Inbetriebnahme der Software
Nach der Installation von Hybrid Cloud Security und IIS konnten wir im Rahmen der Erstkonfiguration über den dafür vorgesehenen Wizard, der nach dem Setup automatisch startet, den zu verwendenden Datenbank-Server und die dazugehörigen Credentials – in unserem Fall das zu verwendende “sa”-Konto – angeben. Anschließend erzeugten wir mit Hilfe des Assistenten eine neue Datenbank für die Lösung und gaben an, über welche IP-Adresse und welchen Port die Web-Konsole des Produkts erreichbar sein sollte. Danach sagten wir dem Assistenten, er solle alle verfügbaren Dienste, wie “SolarWinds Module Engine Service”, “Message-Bus” oder auch “NPM Collector Plugin”, installieren. Zum Schluss wollte er dann noch wissen, ob wir die Datenbank für die Protokoll- und Ereignisüberwachung auf dem gleichen Server betreiben wollten, wie die Hybrid-Cloud-Security-Datenbank. In unserer Testumgebung machten wir das und legten auch gleich eine entsprechende Datenbank an. Zum Schluss erzeugten wir noch eine dritte Datenbank, diesmal für den NetFlow-Traffic-Analyzer, danach war die Erstkonfiguration abgeschlossen und wir konnten mit der Software arbeiten.

Die Ersten Schritte im normalen Betrieb
Beim ersten Zugriff auf das Web-Interface der Lösung müssen die Verantwortlichen zunächst einmal ein Passwort für den “Admin”-Account vergeben. Das ist sehr sinnvoll, da auf diese Weise vermieden wird, dass irgendwelche Installationen mit Standard-Passwörtern betrieben werden. Sobald das erledigt war, startete der Discovery-Wizard, der dabei hilft, die im Netz vorhandenen Komponenten zu erkennen. Für die Discovery können die Administratoren entweder IP-Adressbereiche, Subnetze, einzelne IP-Adressen oder das Active Directory verwenden. Wir scannten im Test unser Subnetz und gaben zusätzlich unseren Domänen-Controller an, damit die Active-Directory-Komponenten direkt übernommen werden konnten.
Im nächsten Schritt möchte der Assistent wissen, welche Virtualisierungsumgebungen er mit in den Discovery-Vorgang aufnehmen soll. Dabei unterstützt das System Nutanix, VMware und Hyper-V. Im Test gaben wir an dieser Stelle unseren Hyper-V-Server und einen ESXi-Hypervisor an. Anschließend teilten wir dem Wizard noch die ssh-Zugangsdaten unserer Netzwerkgeräte, die bei uns verwendeten Netzwerk-Community-Strings und die Windows-Domänen-Credentials mit. Danach ließen wir die Discovery durchlaufen.
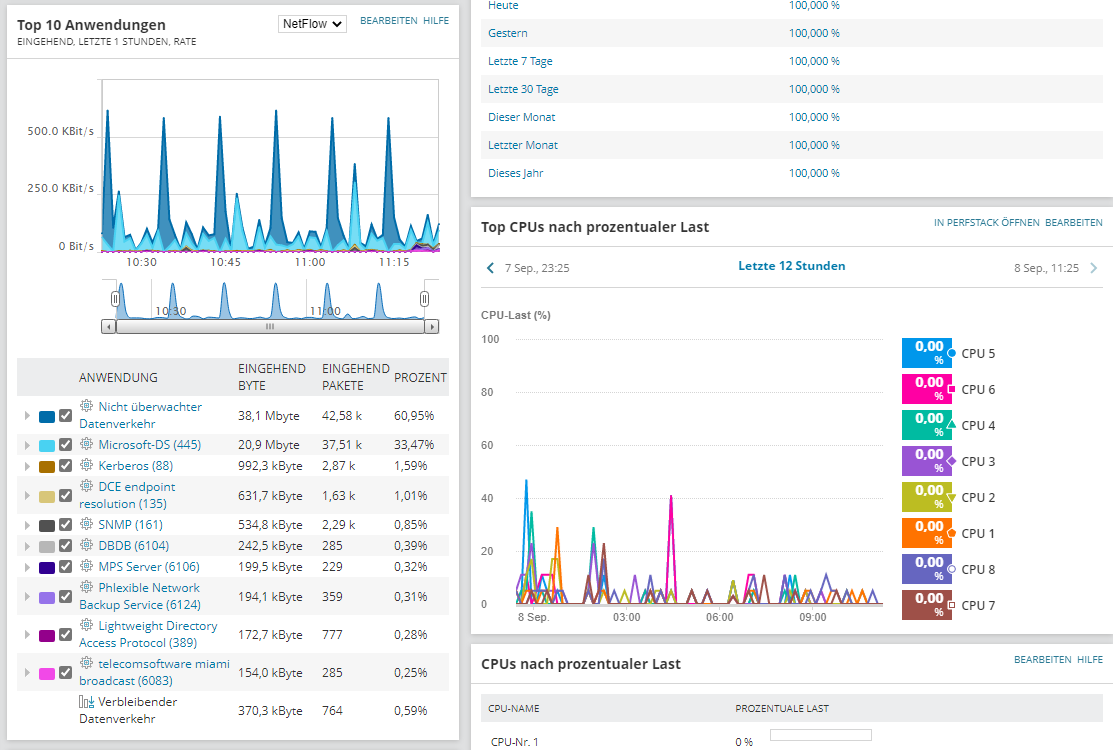
Im Test dauerte der Vorgang über ein Subnetz mit etwa 2000 Adressen ungefähr eine halbe Stunde. Dabei wurden alle vorhandenen Komponenten wie erwartet gefunden. Nach dem Abschluss des Scans zeigte uns der Wizard die gefundenen Gerätetypen in einer Übersicht an und wir konnten auswählen, welche davon wir in unsere Überwachungsumgebung importieren wollten. Im Test banden wir alles ein. Jetzt fragte uns der Assistent nach den für das Monitoring zu importierenden Interfaces, Ports und Volumes. Anschließend integrierten wir die bereits erkannten Anwendungen, wie den SQL Server und das Active Directory, in die Umgebung. Zum Schluss teilten wir dem Wizard noch mit, dass er das Netz nach diversen Anwendungen durchsuchen sollte. Dazu gehörten unter anderem der Apache Webserver und die Dienste und Leistungsindikatoren von Windows Server. Jetzt übernahm das System die erkannten Komponenten und führte den zuletzt definierten Anwendungs-Scan im Hintergrund aus.
Die Arbeit nach der ersten Erkennung
Nach der Installation empfiehlt der Hersteller, nach der ersten Erkennung des Netzes zunächst einmal sämtliche Alarme zu deaktivieren, da diese nur Vorlagen sind und im Zweifelsfall nicht zu dem jeweils vorhandenen Netzwerk passen. Wir folgten dieser Empfehlung und ließen das System erst einmal eine Woche Daten sammeln. Wir legten davor allerdings noch einen automatischen Netzwerk-Scan an, der unser Netz täglich durchsuchte, damit die Überwachungsumgebung auf dem aktuellen Stand blieb.
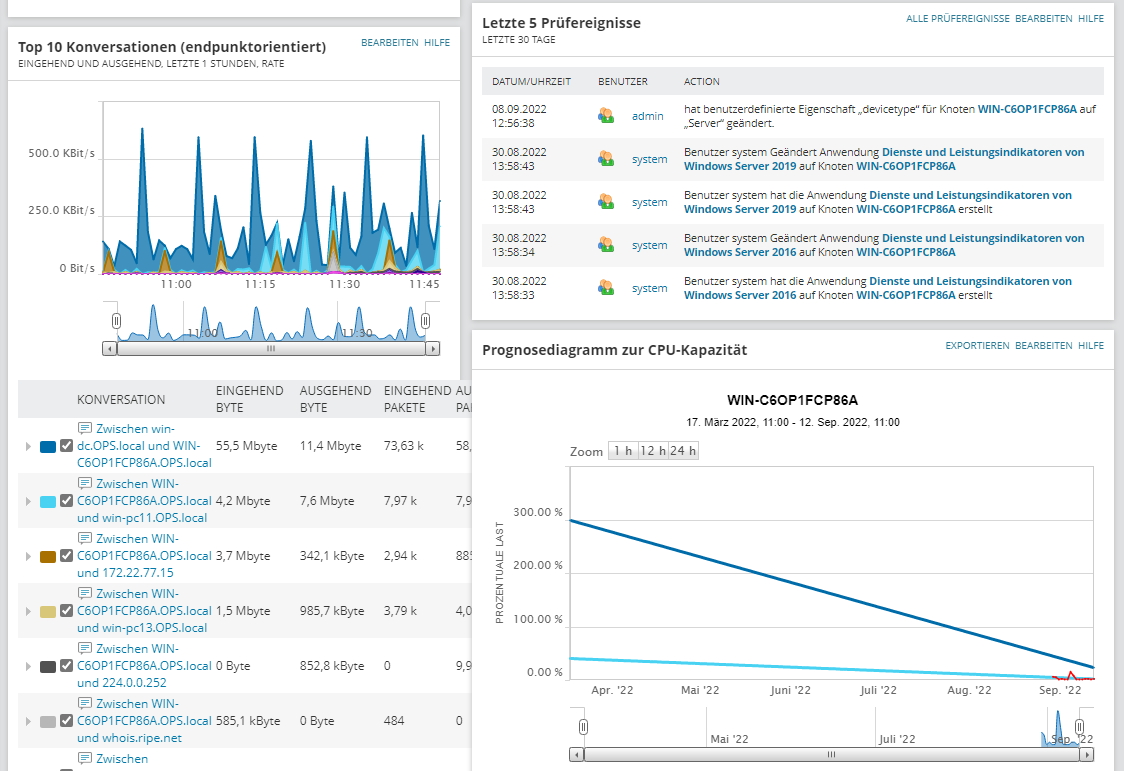
Während das System Daten sammelt, misst es unterschiedliche Datenpunkte und erstellt nach sieben Tagen eine Baseline. Diese lässt sich nutzen, um Schwellwerte für Alarme zu setzen. Abgesehen davon ermöglicht sie auch das Betreiben von Forecasting, also das Erstellen von Voraussagen darüber, wie lang es noch dauern wird, bis der Speicher erweitert werden muss und Ähnliches. Bei diesen Voraussagen gilt, je mehr Daten verfügbar sind, desto besser. Die Schwellwerte für die Alerts lassen sich aber schon nach einer Woche sinnvoll setzen.
Während die Datensammelphase lief, machten wir uns im Test daran, das Produkt so zu konfigurieren, dass es unseren Erwartungen entsprach. Dazu entfernten wir alle Widgets, die wir nicht brauchten, aus dem Übersichts-Dashboard und fügten Widgets, die für uns von Interesse waren, hinzu. Zusätzlich legten wir unter “Einstellungen / Alle Einstellungen / Benutzerdefinierte Einstellungen” einen neuen Eintrag namens “DeviceType” an und definierten die dazugehörigen Werte als “Server”, “Endpoint” und “Netzwerkinfrastruktur”. Anschließen wiesen wir unseren gefundenen Geräten den jeweils zu ihnen passenden DeviceType zu. Danach konnten wir das Widget “Alle Knoten” im Übersichts-Dashboard so konfigurieren, dass es die Geräte nach DeviceType gruppiert anzeigte. Das war deutlich übersichtlicher als die Default-Einstellung nach Herstellern.
Das manuelle Hinzufügen eines Überwachungsknotens
Nachdem wir unseren Überblick verbessert hatten, ging es daran, weitere Knoten zu unserer Überwachungsumgebung hinzuzufügen. Das ergibt Sinn, wenn Geräte eingebunden werden sollen, die bei der Netzwerk-Discovery nicht erkannt wurden, die gerade neu hinzukamen oder die sich in gehosteten Umgebungen befinden. Im Test verwendeten wir an dieser Stelle unser Blog “https://sysbus.eu”. Die Definition des Eintrags läuft unter “Einstellungen / Knoten verwalten / Knoten definieren”. Hier fragt das System nach dem Namen oder der IP-Adresse sowie der zu verwendenden Abrufmethode. An Abrufmethoden steht neben ICMP, SNMP und WMI unter anderem auch ein optionaler Agent für Windows und Unix beziehungsweise Linux zur Verfügung. Letzterer kann Verwendung finden, wenn es darum geht, Hosts in Remote-Umgebungen oder der Cloud zu überwachen. Darüber hinaus gibt es noch die Option “Externer Knoten: Kein Status”. Damit überwacht man Elemente auf Rechnern, beispielsweise Anwendungen, ohne dabei den Knoten selbst im Auge zu behalten. Wir wollten nur wissen, ob unser Blog online war, oder nicht und entschieden uns im Test dazu, die Adresse des Blogs per ICMP zu monitoren. Außerdem erzeugten wir zu diesem Zeitpunkt einen neuen DeviceType namens “Extern”. Nachdem der Knoten hinzugefügt war, erschien das Blog unter diesem DeviceType in der Dashboard-Übersicht.
Die Arbeit mit NetPath
Nachdem alle Knoten wunschgemäß arbeiteten, wendeten wir uns der NetPath-Funktionalität zu. NetPath steht unter “Meine Dashboards / Netzwerk / NetPath-Dienste” zur Verfügung und eignet sich dazu, den Pfad zu visualisieren, den eine Anwendung durch unterschiedliche Netze nimmt. Mit der Funktion lassen sich unter anderem Informationen darüber herausfinden, wie gut die Verbindung zwischen dem Domänencontroller und dem Exchange Server ist, wenn sich diese beiden Komponenten an unterschiedlichen Orten befinden. Alternativ gibt das Feature auch Aufschluss über den Weg, den die Daten von Mitarbeitern nehmen, die Anwendungen in der Cloud einsetzen.