Im Test: SolarWinds SQL Sentry – Microsoft SQL Server durchleuchtet
Das Einbinden der zu überwachenden Datenbank-Instanz
Nach dem Abschluss der Installation aktivierten wir die Software mit den Lizenzinformationen, die uns SolarWinds zur Verfügung gestellt hatte, legten ein Benutzerkonto für SQL Sentry fest und konfigurierten den Zugriff auf unseren SMTP-Server, damit das Produkt uns Warnmeldungen und Ähnliches per E-Mail zuschicken konnte. Zum Schluss verwendeten wir den Befehl “Add target” und gaben den Namen der zu überwachenden Datenbank-Instanz an. Daraufhin verband sich die Software mit der Datenbank und wir hatten Zugriff auf die Überwachungsfunktionen.
Der Funktionsumfang von SQL Sentry in der Praxis
Nachdem wir unsere Datenbank hinzugefügt hatten, landeten wir auf einem Dashboard, das im Workspace in der Mitte Aufschluss über den “Health Score” der gerade überwachten Instanz mit den aktuellen Events gab. Darunter gab es Links zu einem Demo-Video und diversen Webseiten mit Dokumentation, Support, Tipps und Tricks und so weiter.
Der eben erwähnte Health Score kann irgendwo zwischen eins und 100 liegen, je höher die Zahl ist, desto besser. Er errechnet sich aus den in der letzten Zeit aufgetretenen Events, gibt einen schnellen Überblick über den Status des Systems und ermöglicht proaktives Troubleshooting. Daneben finden sich Einträge, die Aufschluss darüber geben, welche Ereignisse als “Critical”, “High”, “Medium” oder “Low” eingestuft worden sind. Alternativ existiert auch eine Übersicht nach Tags wie „Network“, „CPU“ oder auch „Memory“. Klickt man auf einen dieser Einträge, so blendet die Software eine Liste ein, die die Events der jeweiligen Kategorie umfasst, so dass man sofort erkennt, was passiert.
Klickt man auf die Kondition, die zu dem Ereignis gehört, so erhält man eine Detailübersicht, die die Anwender darüber informiert, wann die Kondition auftrat und was der dazugehörige Wert war (beispielsweise ein hoher I/O-Count). Es steht an gleicher Stelle auch ein kurzer Hilfetext mit einer Erklärung oder ein Link zu einer Knowledge Base zur Verfügung.
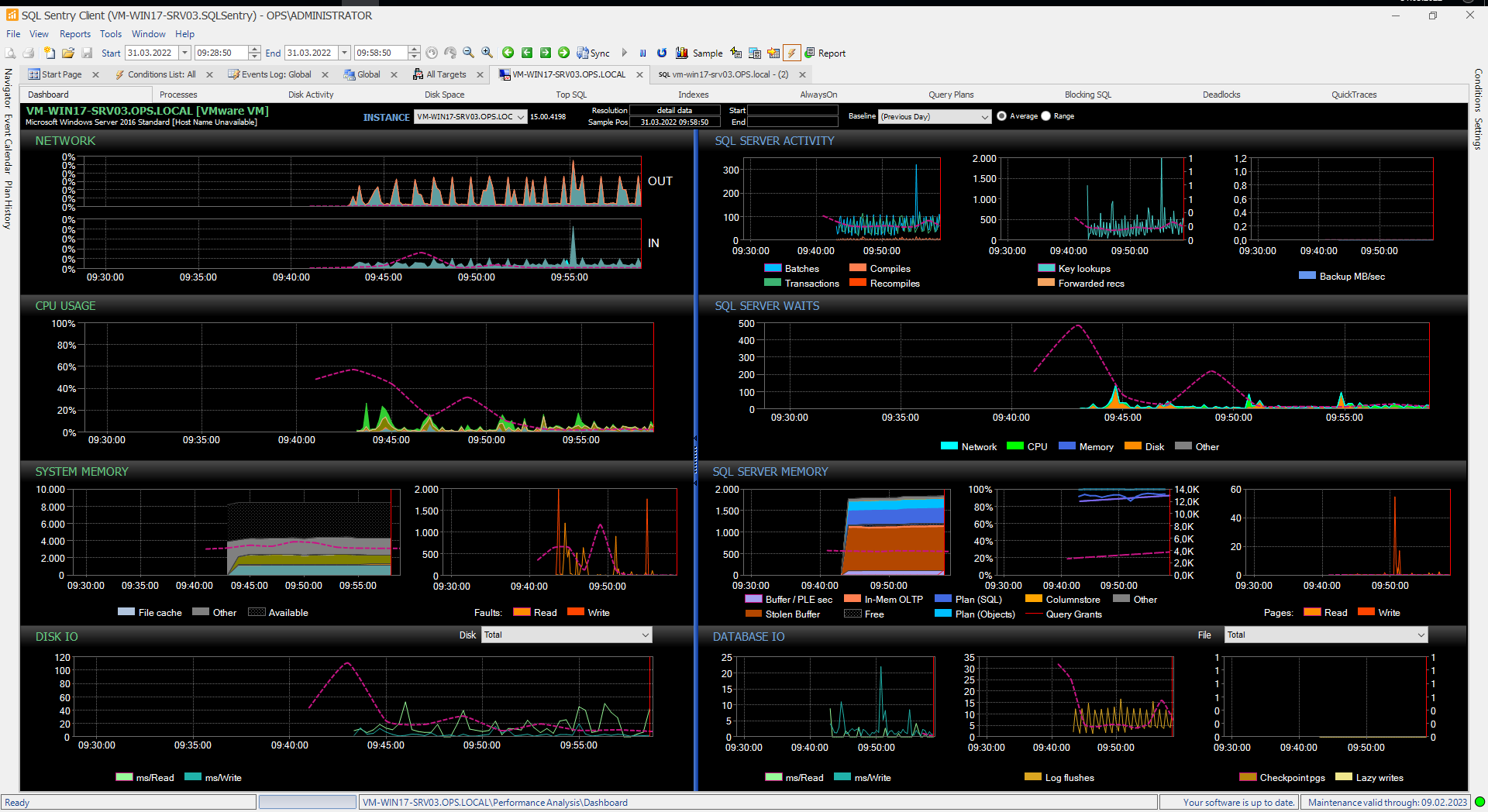
Struktur der Client-Software
Auf der linken Seite findet sich eine Baumstruktur, über die die Anwender unter anderem zu den überwachten Instanzen und den Event-Kalendern navigieren können. Rechts befindet sich ein Bereich zum Zugriff auf alle Konditionen, also “General Conditions”, “Failsafe Conditions”, “Audit Conditions” und “Advisory Conditions”. Auf die Konditionen und den Event-Kalender gehen wir später noch im Detail ein.
Die Seitenleisten lassen sich bei Bedarf ausblenden, um den Arbeitsbereich zu vergrößern. Darüber hinaus kann man sie bewegen, andocken und ihre Größe verändern.
Performance-Analysen in einem Dashboard
Wechselt man auf der linken Seite nach “All Targets / Default Site / {Name des Datenbank-Servers}”, so kann man dort auf die Performance-Analyse des betroffenen System zugreifen. Das hier angezeigte Dashboard (das wir in der Einleitung bereits kurz angesprochen hatten) bietet in grafischer Form Aufschluss über die wesentlichsten Leistungsparameter des Systems und wird standardmäßig alle zehn Sekunden aktualisiert. Dazu gehören der Netzwerkverkehr, die Prozessorlast, die Speicherauslastung und der Disk I/O auf Server-Ebene sowie die Aktivität des SQL Servers, die SQL Server Waits, die Speichernutzung des SQL Servers und der Datenbank I/O. Die genannten Werte umfassen also – wie gesagt – sowohl Leistungsdaten des Servers als auch des Datenbanksystems, die zuständigen Mitarbeiter können hier also auch sehen, wenn irgendwelche anderen Dienste dem SQL Server Kapazitäten wegnehmen.
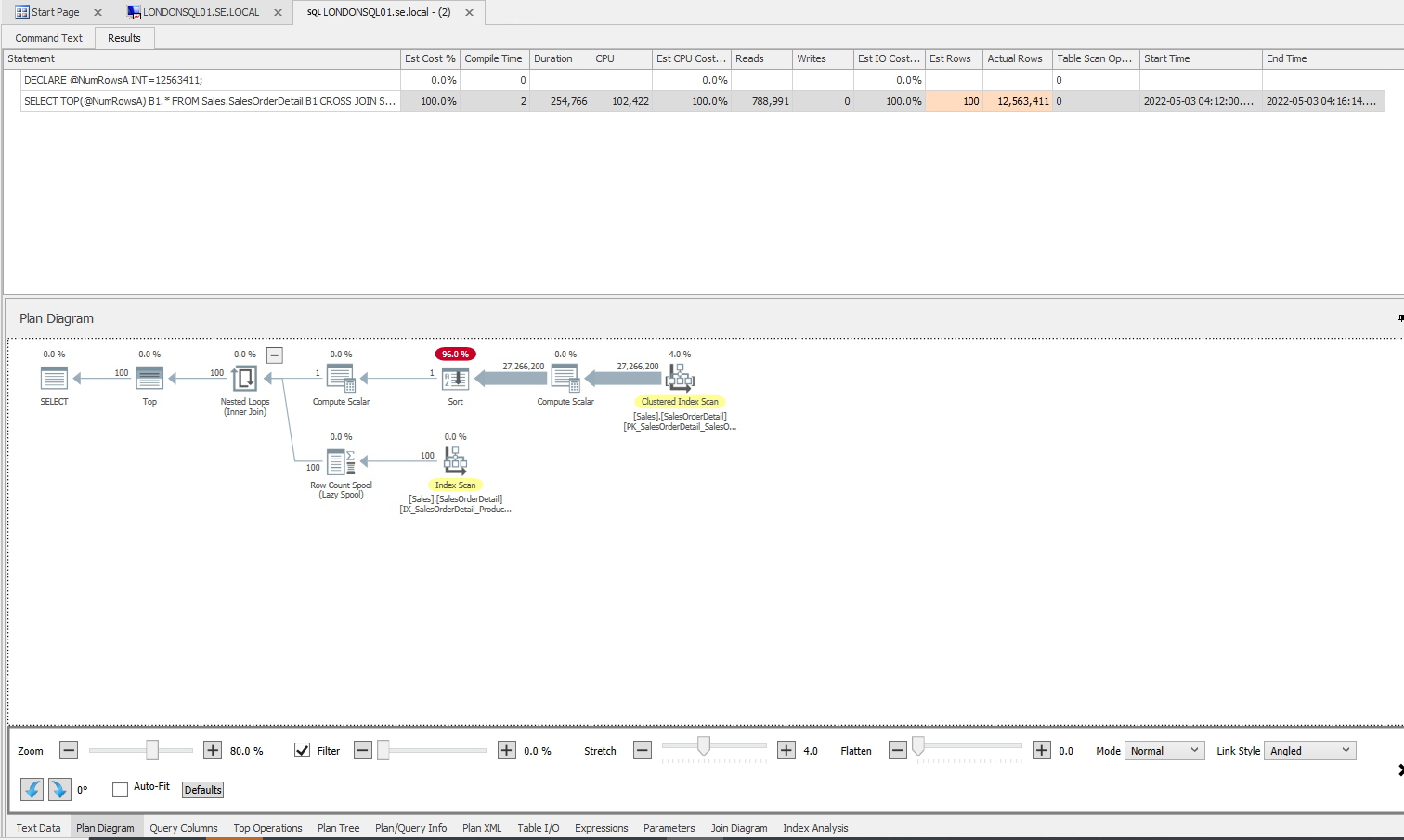
Man kann die Start– und Enddaten der Performance-Analyse jederzeit ändern und so die Länge des Zeitraums und den Zeitpunkt genau bestimmen. Abgesehen davon sind die IT-Verantwortlichen jederzeit dazu in der Lage, in diese grafischen Darstellungen hineinzuzoomen und bestimmte Bereiche zu markieren. Stellen sie zum Beispiel fest, dass zu einem bestimmten Zeitraum die Zahl der SQL Server Waits besonders hoch war und markieren diesen Zeitraum, so hebt das System den gleichen Zeitraum auch in allen anderen Graphen hervor. Auf diese Art und Weise können die Verantwortlichen sofort sehen, ob es zur gleichen Zeit besonders viele SQL Server Writes oder eine hohe CPU-Last gab.
Abgesehen davon gibt es auch die Möglichkeit, eine Baseline über die aktuellen Messwerte zu legen. Aktiviert ein Administrator beispielsweise die Baseline des vorherigen Tages oder der vorherigen Woche, so kann er anhand der eingeblendeten Linie sehen, wie sich das System im Durchschnitt während des gewählten Zeitpunkts verhalten hat (beispielsweise könnte die CPU-Last durchschnittlich bei 28 Prozent gelegen haben) und so Unterschiede zum aktuellen Zustand sichtbar machen. Bei Bedarf lassen sich jederzeit auch eigene Baselines definieren.
Darüber hinaus besteht unter anderem auch die Option, zu den Prozessen, dem Event-Kalender, dem Disk-Space oder auch den Indexen zu springen oder einen “Quick Report” zu den Server Writes zu erzeugen. Auf diese Art und Weise lassen sich schnell Informationen sammeln und Zusammenhänge herstellen, zum Beispiel, dass eine Festplatte des Servers zu dem genannten Zeitpunkt überlastet war und deshalb die Datenbank ausbremste. Das ganze System ist also extrem mächtig.
Weitergehende Informationen sammeln
Es gibt aber noch weitere Möglichkeiten, tiefer in das System einzusteigen. Wechselt man innerhalb des gewählten Zeitraums nach “Top SQL”, so hat man die Option, mehrere verschiedene Informationen einzusehen. Dazu gehören die “Running Queries”, die “Completed Queries”, die “Procedure Stats” und die “Query Stats”. Möchte man sich beispielsweise ansehen, was genau in der Vergangenheit passiert ist, so ruft man die “Completed Queries” auf. Dann erscheint eine Liste mit allen Datenbankabfragen. Diese Liste gibt Aufschluss über die Anwendung, die betroffene Datenbank, den Host, die Dauer, die CPU-Last und vieles mehr. Zusammengehörende Abfragen lassen sich bei Bedarf auch zusammenfassen, so dass man erkennen kann, welche Workloads entstanden sind. So machen die zuständigen Mitarbeiter beispielsweise sichtbar, dass bestimmte Abfragen eines Online-Shops eine besonders hohe Zahl an I/O-Vorgängen verursacht haben.
Unterhalb der Liste mit den Abfragen kann man – nach der Auswahl einer Abfrage – sehen, welche Statements die jeweilige Abfrage enthalten hat, wie lange die Abarbeitung der einzelnen Statements gedauert hat, welche Prozessorlast dabei anfiel und Ähnliches. Es gibt also die Möglichkeit, genau herauszufinden, welche Statements welchen Einfluss auf die Datenbankleistung haben.
Unter den Statements befindet sich noch eine grafisch gestaltete “Query History”. Diese zeigt, wann das betroffene Code-Stück ausgeführt wurde und wie lang der Vorgang gedauert hat. Alternativ gibt es auch die Option, sich die durch den Code verursachte Prozessorlast oder die Reads und Writes anzeigen zu lassen. Damit können die zuständigen Mitarbeiter sehen, wie sich der Code normalerweise verhält und herausfinden, warum Probleme entstehen.
Arbeit mit dem Plan Explorer
Ebenfalls von Interesse: der Plan Explorer. In der Liste der Statements befindet sich ein Button namens “Open”. Klickt man darauf, oder auf den Eintrag “Plan Diagram”, so öffnet sich ein Fenster, das neben dem Statement auch ein Plandiagramm des Ablaufs enthält. In diesem Diagramm werden die Operatoren hervorgehoben, die am meisten Ressourcen verbrauchen. An gleicher Stelle finden sich noch viele weitere Informationen, die Aufschluss über die in der Datenbank ablaufenden Aktionen liefern. Eine “Plan History” hilft in der Praxis beim Optimieren der Statements, da sie die einzelnen Abläufe vorhält und zeigt, welche Auswirkungen vorgenommen Änderungen haben.