PRTG Hosted Monitor im Test – Cloud-basiertes Monitoring
Der erste Netzwerk-Scan
Sobald die Probe mit dem Server in der Cloud kommunizieren kann, besteht die Option, direkt einen automatischen Suchlauf zu starten, der das lokale Netz nach den vorhandenen Komponenten durchsucht. Dieser aktiviert auf den gefundenen Geräten auch gleich eine Auto-Discovery-Funktion, die dort die Sensoren installiert, die nach Ansicht der Verantwortlichen bei Paessler sinnvoll sein könnten. Dabei greifen die Paessler-Mitarbeiter auf Erfahrungswerte zurück, die im Lauf von 20 Jahren gesammelt wurden und optimieren die Konfiguration ständig.
Die Dauer der Discovery hängt von der Größe des Netzes ab. Generell kann man sagen, dass PRTG jede IP-Adresse im Netz anpingt und fünf Sekunden auf Antwort wartet. Die Dauer des Scans liegt also bei der Zahl der IP-Adressen mal fünf. Werden Geräte gefunden, so untersucht PRTG diese genauer, um festzustellen, welche Sensoren darauf zum Einsatz kommen. Der Zeitbedarf für diesen Schritt ist je nach Gerät unterschiedlich, im Schnitt nimmt der Vorgang aber etwa zwei Minuten in Anspruch. Die Zahl der Vorhandenen Geräte mal zwei Minuten kommt also noch zu dem zuvor ermittelten Wert hinzu.
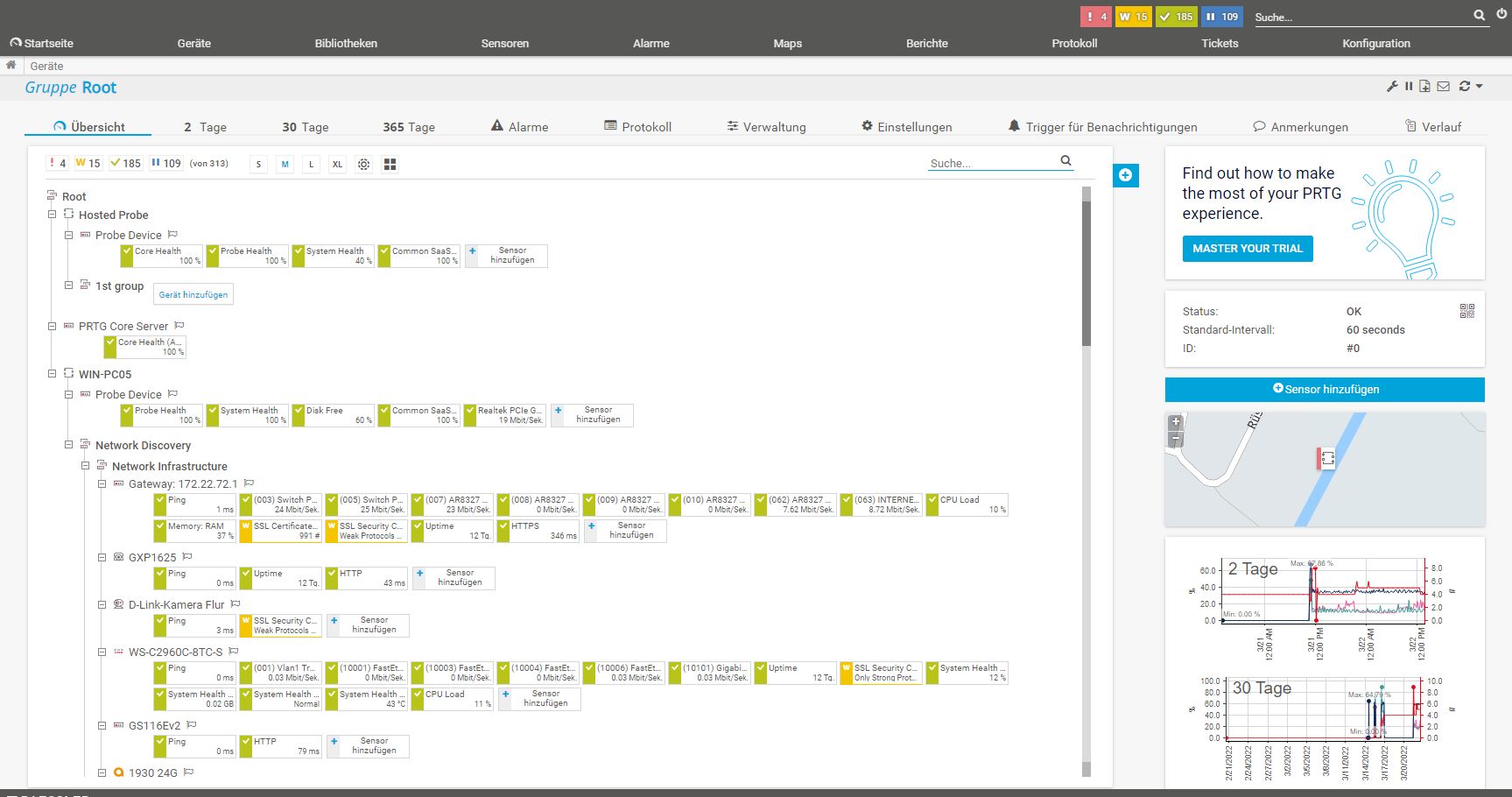
Gehen wir nun kurz auf den Aufbau der Monitoring-Lösung ein. Unterhalb der Gesamtstruktur befinden sich im Betrieb einer PRTG-Instanz Gerätegruppen wie “Windows Server”, die alle überwachten Rechner, die zu der jeweiligen Gruppe gehören, umfassen. Die einzelnen Geräteeinträge enthalten dann wiederum die Sensoren, die – wie gesagt – bestimmte Komponenten oder Funktionen im Blick behalten. Unterhalb der Sensoren gibt es dann noch die so genannten Kanäle, die bei einem Netzwerkkartensensor beispielsweise Aufschluss über Details wie ein- und ausgehenden Verkehr, die Zahl der Pakete oder die aufgetretenen Fehler gibt.
Der automatische Suchlauf erfasst durchaus einen Großteil der Geräte, die im Netz überwacht werden können, ordnet diese dann den genannten Kategorien wie “Windows Clients” oder “Netzwerkinfrastruktur” zu und installiert die wichtigsten Überwachungssensoren darauf. In der Praxis ist es aber erforderlich, die einzelnen Einträge nach dem Suchlauf nochmals durchzusehen, fehlende Geräte manuell zu erfassen, fehlende Sensoren, beispielsweise für das Überwachen bestimmter Anwendungen, anzulegen und überflüssige Sensoren zu löschen.
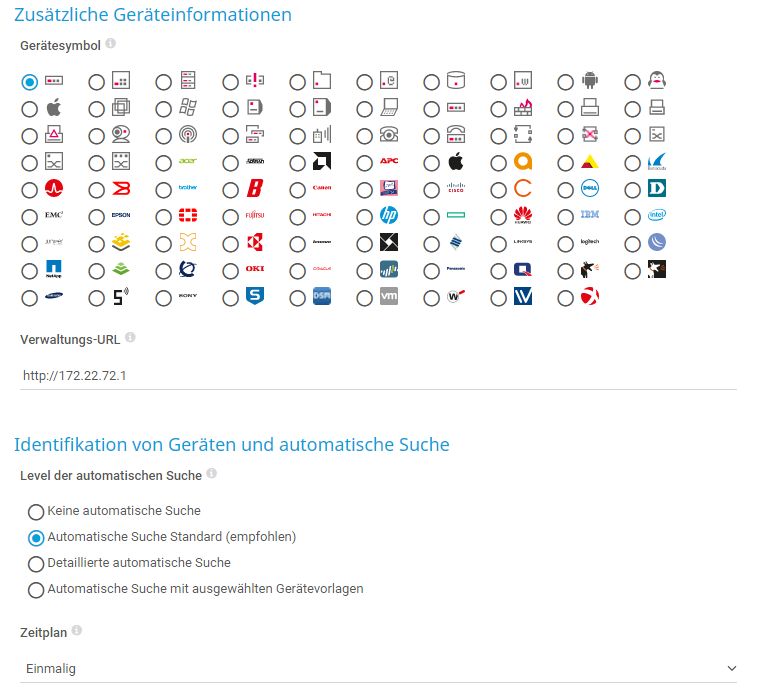
Das Erstellen von Geräteeinträgen
Möchte man ein Gerät erfassen, so geht man im Webinterface der Lösung unter “Devices” zu der Rubrik, in die es gehört, wie etwa “Windows Server” und klickt auf den Eintrag “Add Device”. Dann erscheint ein Dialogfeld, in dem man dem Gerät einen Namen geben kann, festlegt, ob die Kommunikation mit dem Device über IPv4 oder IPv6 ablaufen soll und anschließend die IP-Adresse des Geräts einträgt. Zusätzlich gibt es unter anderem auch die Option, dem Device ein Icon zuweisen. Hier stehen Geräte-Icons, etwa für Netzwerkkameras zur Verfügung, das gleiche gilt aber auch für Herstellerlogos, beispielsweise für Produkte von APC, Checkpoint oder auch Huawei. Zu guter Letzt gibt es auch noch die Möglichkeit, auf dem Gerät eine Auto-Discovery ablaufen zu lassen. Damit die Discovery-Funktionen möglichst viel erkennen kann, ergibt es Sinn, zuvor die Zugriffsdaten für die entsprechenden Systeme in PRTG zu hinterlegen, damit die Monitoring-Software in die Lage versetzt wird, sich bei den Devices einzuloggen und Informationen abzufragen. Die genannten Credentials werden immer an die Untergruppen weitervererbt. Legt man sie auf Ebene von “Root” fest, gelten sie für die gesamte Umgebung. Legt man sie beispielsweise in der Rubrik “Windows” fest, so gelten sie nur für die dazugehörigen Untergruppen, wie beispielsweise “Windows Clients” oder auch “Windows Server”. In der Praxis müssen die Administratoren sich überlegen, wie sie ihre jeweilige Umgebung abbilden wollen (es wäre auch möglich, die Gruppen nach Abteilungen wie “Buchhaltung” und “Vertrieb” zu gestalten) und auf welcher Ebene sie welche Credentials angeben. Das Definieren der Login-Daten geht auf jeden Fall immer unter den Einstellungen der jeweiligen Probe, der jeweiligen Unterrubrik oder auch des betroffenen Geräts.
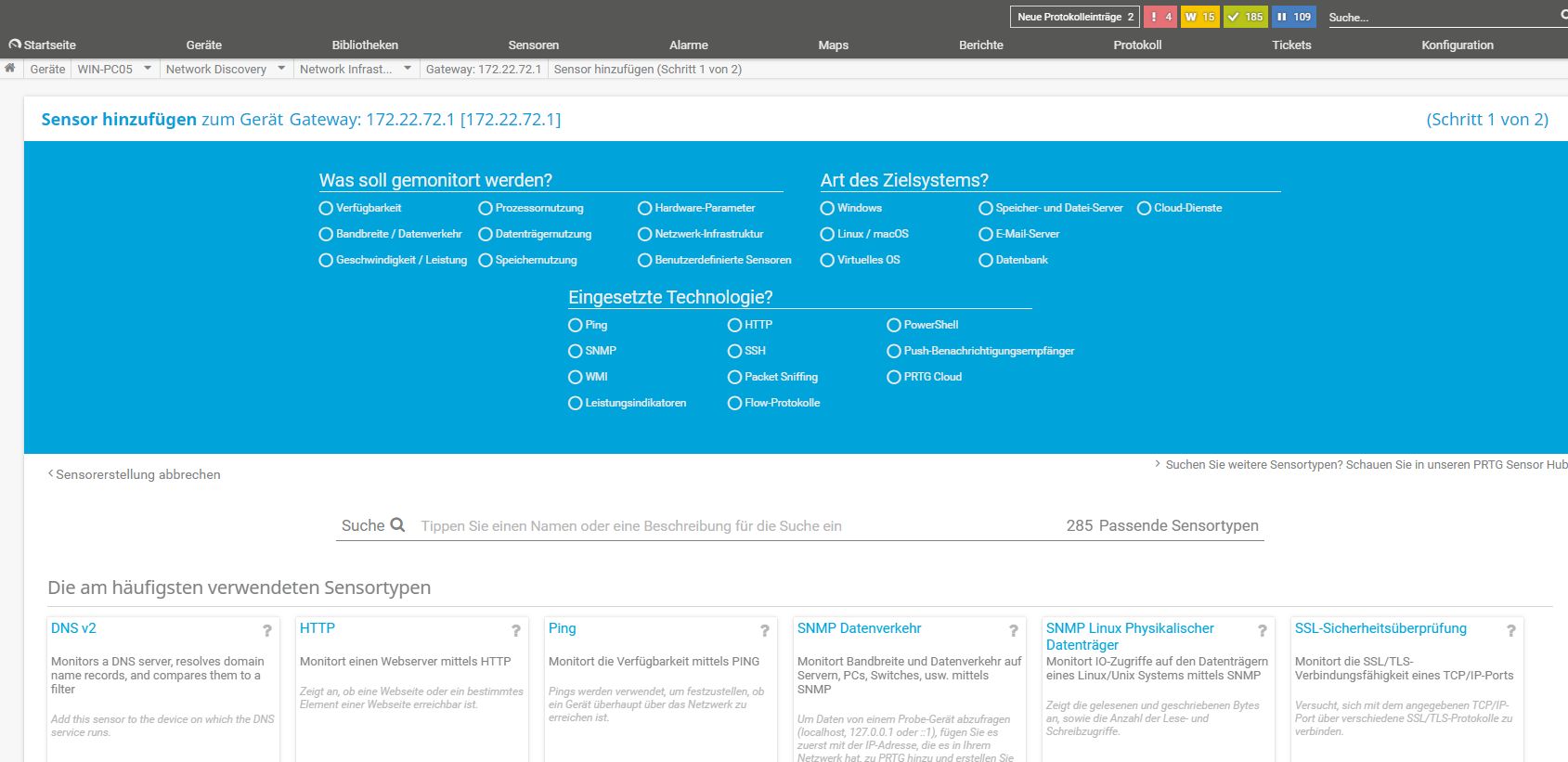
Neue Sensoren lassen sich einfach einbinden
Das Hinzufügen von Sensoren gestaltet sich dann relativ einfach. Man wechselt dazu auf den betroffenen Geräteeintrag und selektiert “Add Sensor”. Danach bietet PRTG eine übersichtliche Auswahl an, die drei Fragen stellt. “Was soll gemonitort werden?” (Beispielsweise Prozessornutzung oder Bandbreite), “Art des Zielsystems?” (Windows, Linux, etc.) und “Eingesetzte Technologie?” (wie etwa SNMP, SSH oder WMI). Hat der Administrator diese drei Fragen beantwortet, so zeigt das System die zu der jeweils passenden Kombination gehörenden Sensoren an und der IT-Verantwortliche kann den Gewünschten auswählen. Das System ist übersichtlich und funktioniert schnell, kennt man den Sensornamen bereits, so steht auch eine Suchfunktion bereit, über die man ihn direkt findet.
Als alle gewünschten Sensoren vorhanden waren, setzten wir noch die Thresholds einiger Sensoren anders, da diese mit den Standardeinstellungen unerwünschte Alarme produzierten (das geht in den Sensoreinstellungen) und definierten einen Report, der uns täglich per Mail über den Status unseres Netzwerks informierte.
Reports lassen sich unter “Reports / Add Report” einrichten. Hier stehen auch diverse Templates zur Verfügung, die das Einrichten des Reports vereinfachen. Dazu gehören unter anderem “Tabelle mit Daten”, “Nur Grafiken”, “Liste der Sensoren” und “Top 100 höchste und tiefste”. Außerdem kann man auch noch angeben, wann der Report erstellt werden soll, welcher Zeitraum in ihm berücksichtigt wird und Ähnliches. Nach dem Einrichten des Reports war die Konfiguration unserer Umgebung abgeschlossen und wir gingen in den Normalbetrieb über.