
Im Test: Talend Enterprise Data Integration 5.4.1
Die Arbeit mit dem Talend Data Integration Studio
Als die Installation und Konfiguration von Talend Enterprise Data Integration abgeschlossen war, konnten wir uns bei dem zuvor erzeugten Projekt anmelden und mit der Arbeit beginnen. Wie bereits erwähnt, setzt das Talend Data Integration Studio auf der Entwicklungsumgebung Eclipse auf. Deswegen ist es für Anwender, die mit Eclipse bereits vertraut sind, verhältnismäßig einfach, sich in der Lösung zurechtzufinden.
Das Data Integration Studio erweitert den Leistungsumfang von Eclipse deutlich und ermöglicht das Erzeugen von Software mit Hilfe vorgefertigter Komponenten. Konkret sieht das so aus, dass die Entwickler im Betrieb auf der rechten Seite des Fensters über eine so genannte Palette verfügen. Dabei handelt es sich um eine Art “Werkzeugkasten”, der vordefinierte Komponenten enthält, die für die Datenintegration von Bedeutung sind. Diese wurden nach verschiedenen Kriterien in Gruppen eingeteilt, lassen sich aber auch durchsuchen, so dass die Anwender jederzeit dazu in der Lage sind, die Einträge beziehungsweise Funktionen zu finden, die sie gerade benötigen. Haben die User Erfahrung mit dem Data Integration Studio und wissen, wie die zu den Komponenten gehörenden Icons heißen, so reicht es auch, im Arbeitsbereich mit der Maus auf eine freie Stelle zu klicken und den Namen einzutragen. Daraufhin fügt das Studio die dazugehörige Komponente direkt im Arbeitsbereich ein. Alternativ ziehen die Benutzer die Icons per Drag-and-Drop aus der Palette in den Arbeitsbereich.
Die Komponenten stellen eine Vielzahl von Funktionen bereit. Dazu gehören etwa Datenbankanbindungen an AS400-, Access-, DB2-, Firebird-, Hive-, Informix-, MySQL- und SAS-Systeme, die Option zum Einbinden von Dateien als Datenquellen oder Exportziele sowie Features zum Umwandeln von Daten. Während der praktischen Arbeit fügen die zuständigen Mitarbeiter die von ihnen benötigten Icons– die jeweils bestimmte Datenquellen oder Exportziele symbolisieren – sowie die einzusetzenden Umwandlungsfunktionen zum Arbeitsbereich hinzu, erzeugen mit der Maus Verbindungen zwischen den Komponenten, die den Datenfluss darstellen und geben jeweils die Parameter an, die sie zum Betrieb benötigen. Bei einer MySQL-Datenbank könnten das zum Beispiel die Serveradresse und die Zugangsdaten sein. Anschließend erzeugt das Data Integration Studio aus diesen Informationen den Code, der für den Job zum Einsatz kommt und ermöglicht es auch, den entsprechenden Task gleich auszuführen. Läuft er problemlos durch, so lässt er sich anschließend an einen Execution Server übergeben. Treten Fehler zu Tage, so lassen sich die umfangreichen Debugging-Funktionen des Data Integration Studios nutzen, um die vorhandenen Fehler zu beseitigen. Bei Bedarf ist es auch jederzeit möglich, eigenen Code in das Projekt zu integrieren, aufgrund der Vielzahl der vordefinierten Funktionen und Datenverbindungen dürfte dieser Schritt aber nur in seltenen Fällen erforderlich sein.
Ein Beispiel aus der Praxis
Zeigen wir nun einmal anhand eines praktischen Beispiels, wie die Arbeit mit dem Data Integration Studio abläuft. Dabei wollen wir Kundendaten aus einem MySQL-Server auslesen, sie so umwandeln, dass sie den Anforderungen unseres Zielsystems entsprechen und sie anschließend in Salesforce exportieren.
Dazu ist es zunächst erforderlich, eine Verbindung zur MySQL-Datenbank herzustellen, die die Quelldaten enthält. Dabei handelt es sich um Kundendaten mit Namen, Adressen und bestellten Produkten. Um die Datenbankverbindung anzulegen, müssen die User zunächst im linken Fensterbereich unter Metadaten auf “Db Connections” wechseln und dort nach einem Rechtsklick den Wizard zum Erstellen einer neuen Datenbankverbindung aufrufen. Dieser fragt zunächst nach dem Namen der Verbindung und möchte anschließend den verwendeten Datenbanktyp wissen. Danach fragt er nach der Datenbank-Version, den Anmeldungsdaten und der zu verwendenden Datenbank auf dem Server. Sobald diese Angaben gemacht wurden, lässt sich die Verbindung testen und abspeichern.
Damit die Datenintegrationslösung später weiß, welche Informationen in der Datenbank zur Verfügung stehen, ergibt es an dieser Stelle Sinn, das Schema der Datenbank im Repository abzulegen. Das geht durch einen Rechtsklick auf die Datenbankverbindung und die Auswahl des Befehls “Schema ermitteln”. Danach finden sich die einzelnen Schema-Komponenten unterhalb des Eintrags der Datenbankverbindung unter “Tabellen-Schemas”.
Nachdem die Quelldatenbank definiert wurde, kann es daran gehen, den Datenumwandlungsjob zu definieren. Dazu führen die Benutzer, ebenfalls am linken Bildschirmrand, einen Rechtsklick auf “Job-Design” aus und selektieren den Eintrag “Erstelle Job”. Daraufhin öffnet sich ein Fenster, in dem die Mitarbeiter im Wesentlichen den Jobnamen und eine Beschreibung eingeben können. Sobald das erledigt ist, speichern sie den Job.
In der Mitte des Fensters öffnet sich nun automatisch ein neuer Reiter mit einem leeren Arbeitsbereich für das Job-Design. Nun geht es daran, die zuvor erzeugte Datenbankverbindung per Drag-and-Drop aus dem Bereich Metadaten in den Arbeitsbereich zu ziehen. Verwendet der User dazu einen Schema-Eintrag aus der zuvor angelegten “Tabellen-Schemas”-Übersicht, so wird neben den Verbindungsinformationen auch direkt die richtige Schemadefinition übernommen. Während des Drag-and-Drop-Vorgangs fragt das Studio nach der zu erstellenden Komponente. Hier stehen Einträge wie “MysqlOutput”, MysqlRow”, “ELTMysqlMap” und ähnliches zur Verfügung. Da wir die Verbindung als Datenquelle nutzen wollten, selektierten wir an dieser Stelle die Komponente “MysqlInput”. Nachdem dieser Schritt erledigt war, fand sich im Arbeitsbereich ein Icon wieder, dass die MySQL-Datenquelle symbolisierte und das bereits über alle erforderlichen Verbindungsparameter verfügte.
Im nächsten Schritt zogen wir aus der Palette das Icon der Komponente “SalesForceOutput” in den Arbeitsbereich und gaben Parameter wie die Salesforce Webdienst-URL, unsere Login-Credentials und den Timeout an.
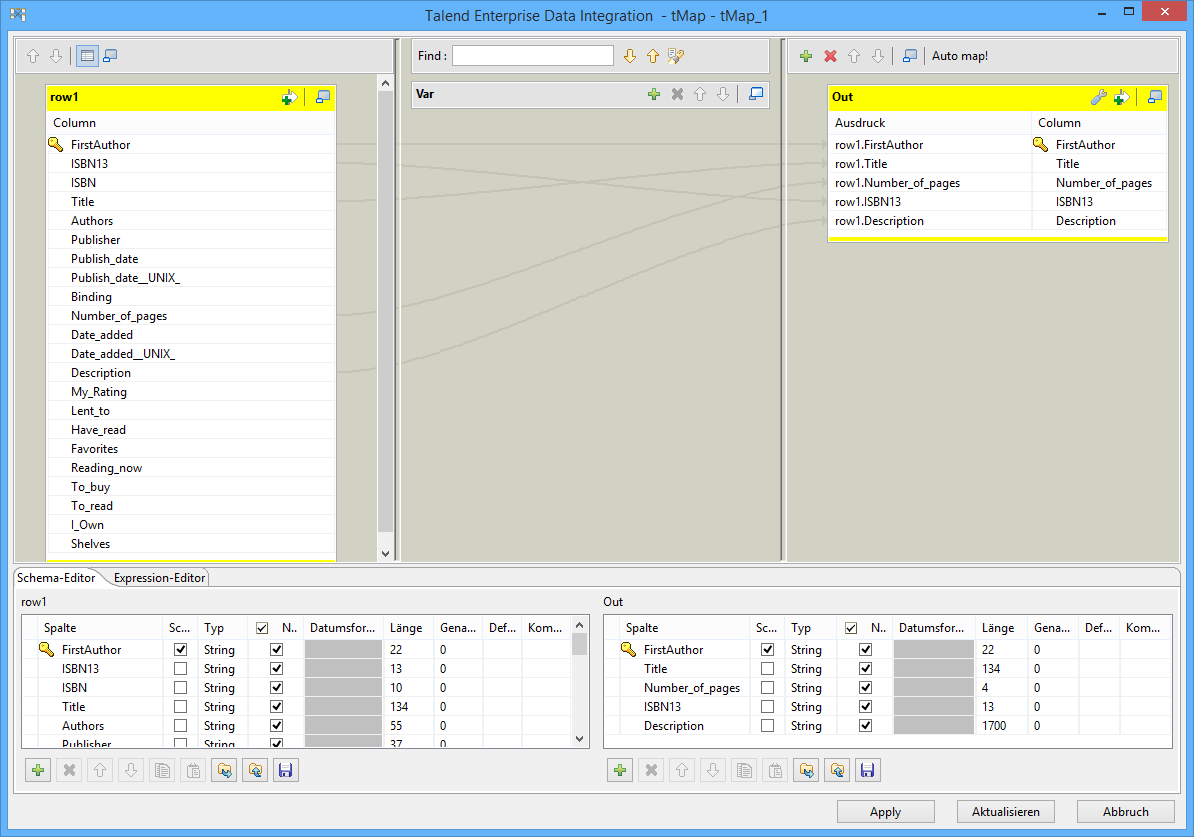
Jetzt konnte es an die Definition der Datenumwandlung selbst gehen. Dazu fügten wir zwischen den beiden bereits vorhandenen Icons einen Eintrag für eine Map-Komponente hinzu und zeichneten mit der Maus Verbindungen zwischen der MySQL-Source, dem Icon der Map-Komponente und der Salesforce-Destination. Anschließend konnten wir auf die Map-Komponente doppelklicken. Daraufhin öffnete sich ein neues Fenster, in dem sich links und rechts jeweils die Dateninhalte von Quelle und Ziel fanden. An dieser Stelle hatten wir die Möglichkeit, die benötigten Daten aus der Quelldatenbank auszuwählen und zu definieren, in welche Felder des Zielsystems diese Informationen jeweils einzutragen waren. Auf diese Weise sorgten wir dafür, dass die Vornamen und Nachnamen der Kunden sowie ihre Adressdaten in den richtigen Feldern landeten.
Damit war die Definition des Jobs abgeschlossen und wir konnten ihn über den Reiter “Starte” unterhalb des Arbeitsbereichs erstmals ausführen und überprüfen, ob er sich wie gewünscht verhielt. Er steht zu diesem Zeitpunkt übrigens auch schon im Administration Center zur Verfügung und lässt sich dort nutzen, dazu aber später mehr.
Dieses Beispiel zeigt, dass das Data Integration Studio eine sehr mächtige Entwicklungsumgebung für Datenumwandlungsjobs darstellt. Die Komponenten machen wohl in den meisten Fällen die direkte Arbeit mit dem Quellcode überflüssig, so dass auch Mitarbeiter mit geringen Entwicklerkenntnissen ohne Probleme dazu in der Lage sein dürften, mit dem Produkt zu arbeiten.
Cloud-Anbindung
Bevor wir uns dem Administration Center zuwenden, gehen wir an dieser Stelle noch auf die Cloud-Unterstützung von Talend Enterprise Data Integration ein. Innerhalb der Palette steht ein Menüpunkt “Cloud” zur Verfügung, der neben Salesforce-Verbindungen auch die Arbeit mit AmazonRDS, AmazonS3, GoogleStorage, Marketo und SugarCRM ermöglicht.
Dank des Amazon-Supports lassen sich zum Beispiel Daten per “Get” aus dem AmazonS3-Speicher einlesen, lokal verändern und dann per “Put” wieder in den Cloudspeicher hochladen. Es besteht auch die Möglichkeit, den “Execution Server” als Amazon-Instanz zu realisieren, die die Daten direkt verarbeitet. In diesem Fall laufen alle Arbeitsschritte in der Cloud ab. Kosten fallen immer nur an, wenn wirklich Daten verarbeitet werden. Eine vergleichbare Vorgehensweise ist im Storage-Bereich auch mit den Cloud-Angeboten von Google denkbar.

